

引言
堆的学习对于二叉树的学习起着十分重要的作用,这篇文章将对堆进行深入的讲解
堆的本质
- 逻辑上
堆是一个完全二叉树,最后一行从左到右是连续的
- 物理上
与传统二叉树不同的是,堆是一个数组,而不是严格意义上的二叉树,因为堆是一个完全二叉树,不会有多余的指针,直接设定为数组更节省空间,也更好通过下标来找到对应的数据,代码也更简单,所以我们将堆设置为一个数组
- 注意事项
这里的堆与c语言中的函数栈帧中的堆是两个概念,不要搞混了
堆的类型
- 大堆
1.任何一个父亲都大于等于孩子
2.根是最大的
- 小堆
1.任何一个父亲都小于等于孩子
2.根是最小的
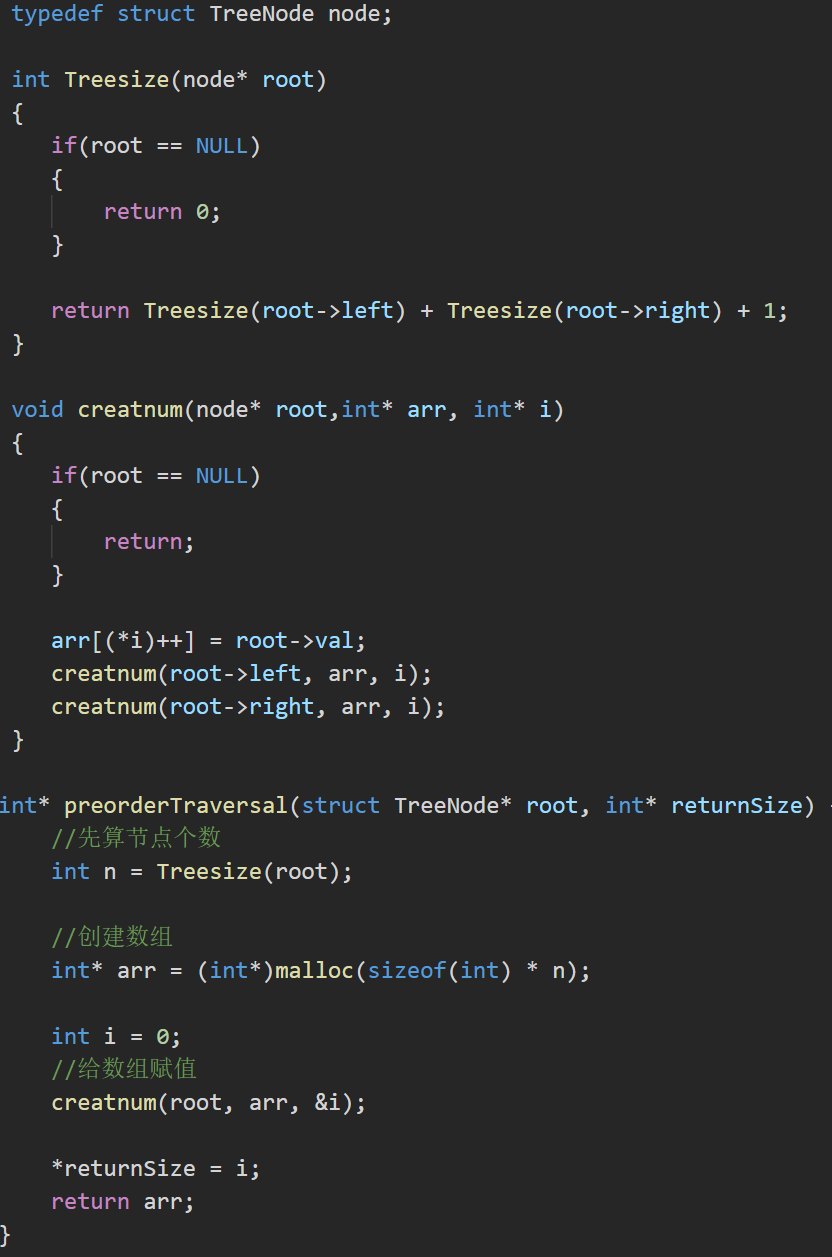
堆的具体实现
- 堆的结构体
具体思路:
从前面的知识我们可以得知,堆的本质是一个数组,因此我们可以采用与类似于顺序表的结构体,设置一个数组指针,一个表示空间的数,一个表示有效数据的数
具体实现如下:
- 堆的初始化
具体思路:
就是与顺序表的初始化是相同的,给数组指针赋值NULL,给另外两个数赋值0
具体实现如下:
- 堆的销毁
讲完了初始化,让我们来实现一下堆的销毁
具体思路:
其实与顺序表的销毁是相同的,先释放指针数组,然后赋值为NULL,最后再将两个数值赋值为0
具体实现如下:
- 堆的插入
从这里开始才是真正有关于堆的实现的具体需要我们新掌握的知识,我们这里就用实现小堆作为例子吧
具体思路:
首先堆是一个数组,我们在插入数据前要先检查数组空间是否足够,这一点我们已经在前面的学习中熟练掌握了,这里就不过多赘述了。
然后因为是数组,我们就在末尾插入新的数据,这时我们就要用到新的思路: ”向上调整”
指的是将尾节点不断与自己的父节点进行比较,因为这里实现的是小堆,所以当子节点小于父节点时,就将两个节点的数据进行调换,然后此时将子节点的下标改为父节点的下标,再循环刚才的步骤,直到父节点小于子节点的数据,或者是子节点已经到达根,这两种条件都可以让循环跳出
具体实现如下:

注意判断结束条件:
这里使用的是 child>0 而不是 parent>0 ,这是因为parent只是一个中间变量,当child == 0时才能判断已经跑到了根节点,当child == 1时,parent也会等于0,就会漏掉最后一次比较,可能会造成最后的排序错误
注意形参的类型:
这里的形参类型第一个是数组指针,而不是堆的结构体,第二个形参指的是数组的大小,第三个形参指的则是要开始向上调整的数据对应的下标,不要理解错了
- 堆的删除
堆的删除与堆的插入是有相同之处的,只不过在堆的插入中我们使用的是向上调整,但是堆的删除中我们使用的是向下调整,至于为什么,马上就会解答了
具体思路:
堆的删除一般指的是删除堆头的元素,也就是根,我们首先可能会想到的是像顺序表一样将首元素后的每个元素依次向前移动一步,但是仔细一想这在堆里面是无法实现的,因为如果全部向前一步的话,堆的顺序就会产生变化,堆就可能会崩塌
所以,为了不让堆的大体结构发生变化,我们采取的方法是将首元素和末尾元素交换,然后再让交换完成的首元素向下调整,这样就可以保证堆依然成立,当然也要让有效元素减一
具体实现如下:

注意判断条件:
注意这里的结束条件是有两个的,与堆的插入结束条件是有相似之处的,就不过多赘述了,主要是判断是否要交换数据是有两个条件的,首先我们要先找出最小的那个子节点,我们通过正常的算法算出来的是左节点,所以这里我们要+1对比左右节点哪个更小,然后在对比前也要确认右节点的下标是小于当前有效元素大小的,如果不注意这个的话,可能在最后交换的节点是要删除的首元素
注意形参:
其实与向上调整的形参是一样的,可以回看一下前面的
- 堆的数据个数 && 堆的判空
这两个都是老生常谈了,这里就不多说了
具体实现如下:

堆的应用
- 利用堆对数组进行排序
具体思路:
因为我们这里是利用堆进行排序,但是对于大多数数组来说,这些数组都不是一个堆,所以我们要先创建一个堆,在创建堆前我们要先清楚我们要排升序还是降序,这里给出一个结论:
降序建小堆,升序建大堆
至于原理等一下再进行解释,我们这里先默认建小堆,因为前面写的向上调整和向下调整都是小堆形式的,我们要建堆有两种方式:
1.用向上调整建堆
具体实现方法就是从第一个数开始,依次向上调整,遍历完整个数组,这样所有数据都进行了向上调整,这样我们就实现了建堆了
具体实现如下:

2.用向下调整建堆
这里的具体实现方法与向上建堆有些许不同,我们要先找到第一个有子节点的叶子,这样向下调整才有意义,至于为什么前面的向上调整建堆可以直接从首元素开始,是因为首元素就只有一位,不会造成什么影响,但是向下调整就不一样了,要考虑到可能有大量的叶子没有子节点,向下调整就是白费内存了,而我们找到第一个父节点的方法就是,用有效元素-1得到尾节点,再用尾结点-1除以2找到父节点
具体算式为: (n – 1 – 1) / 2
然后再遍历在之前的叶子,进行向下调整
具体实现如下:

选择:
正常来说我们一般选择都是第二种,这是为什么呢,那是因为第二种的时间复杂度更低,可能乍一看两种方法的时间复杂度是一样的,但是具体算的话就会发现不同了,这里给出一张图进行解释:
用简单点的话解释就是,一个是多 * 多,一个是多 * 少,明显能得出多 * 少那个时间复杂度更低,也就是向下调整的方式更节省内存
堆排序:
这里要运用前面堆的删除的知识,我们从前面可以得知,我们会将根与末尾数据进行调换,而根是堆中最小或者最大的数,这样我们就能把目前堆中的最值放在末尾了,这里就解释了为什么升序建大堆,降序建小堆,然后我们再将有效数据减一,继续循环进行,直到有效数据为1
具体实现如下:

整个函数的具体实现如下:

- 文件中找TopK问题
这个问题就是在文件中找出最大的k个数,首先我们有这几种方法可以尝试
1.建立一个N个数的大堆,然后返回堆顶元素,再删除元素,循环k次就可以了,但是这个方法创建的N个数的大堆占据内存会过大,不推荐
2.先用前k个数建立一个小堆,然后再依次读取数据,将读取的数据与堆顶进行比较,因为堆顶是小堆里的最小值,如果大于堆顶就取代堆顶,再向下调整,找出新的堆顶,不断循环,直到读取完文件中所有的数据
具体实现如下:

有关于文件的读取就不在这里进行解释了
小技巧:
1.减少随机数重复的方式:
for(int i = 0; i < 10000; i++)
int a = rand() + i;
2.调试技巧
我们可以先规定生成的数字在一个范围内,然后生成完后再手动将里面的几个数据进行加大,注意这里手动调整大小的时候不要越界了!
总结
虽然堆不是完全意义上的二叉树,但是堆排序对于数据结构的学习是十分重要的,对比于冒泡排序,时间复杂度就低了很多,真正的二叉树的学习将在下一篇文章,加油吧!

评论(0)
暂无评论